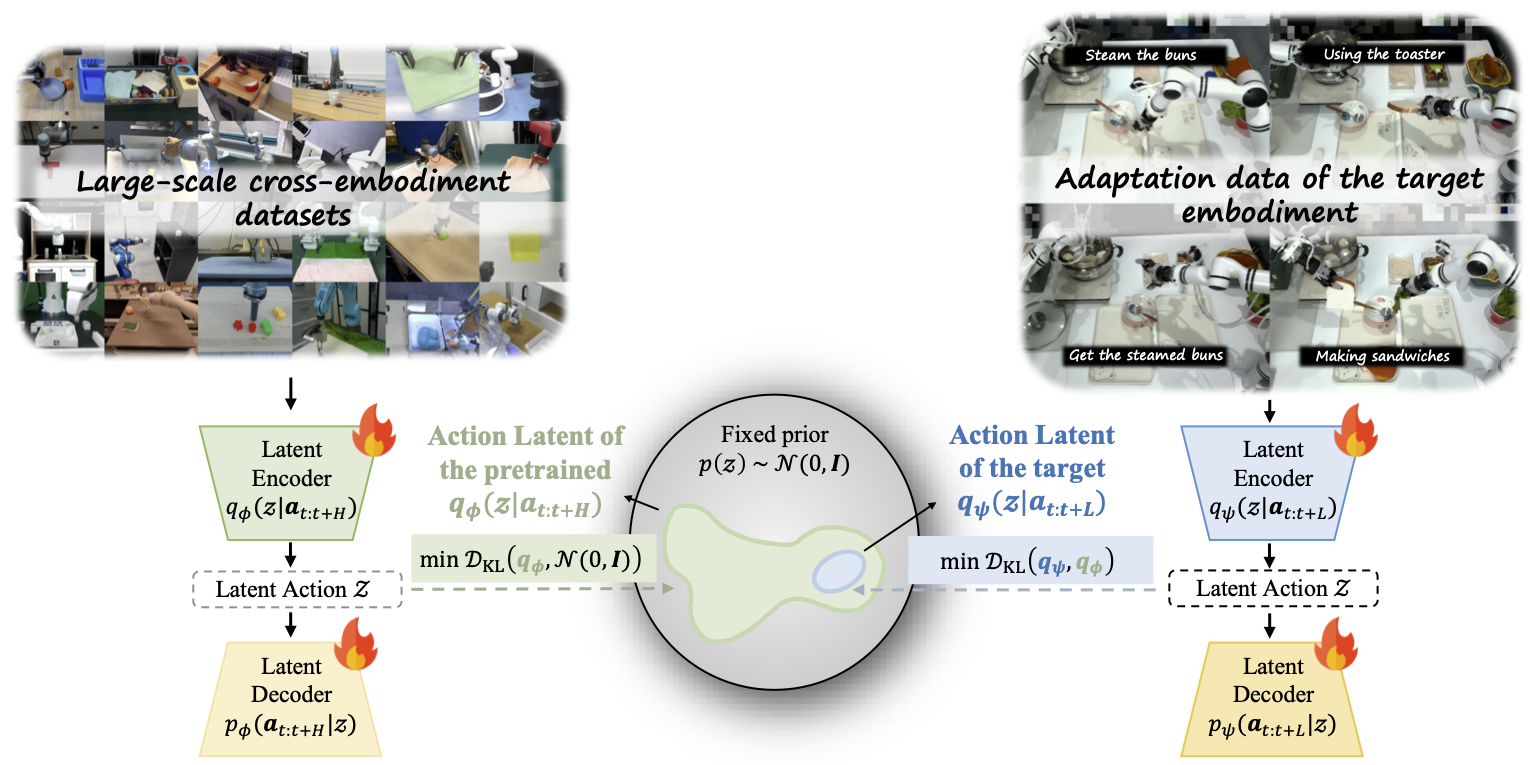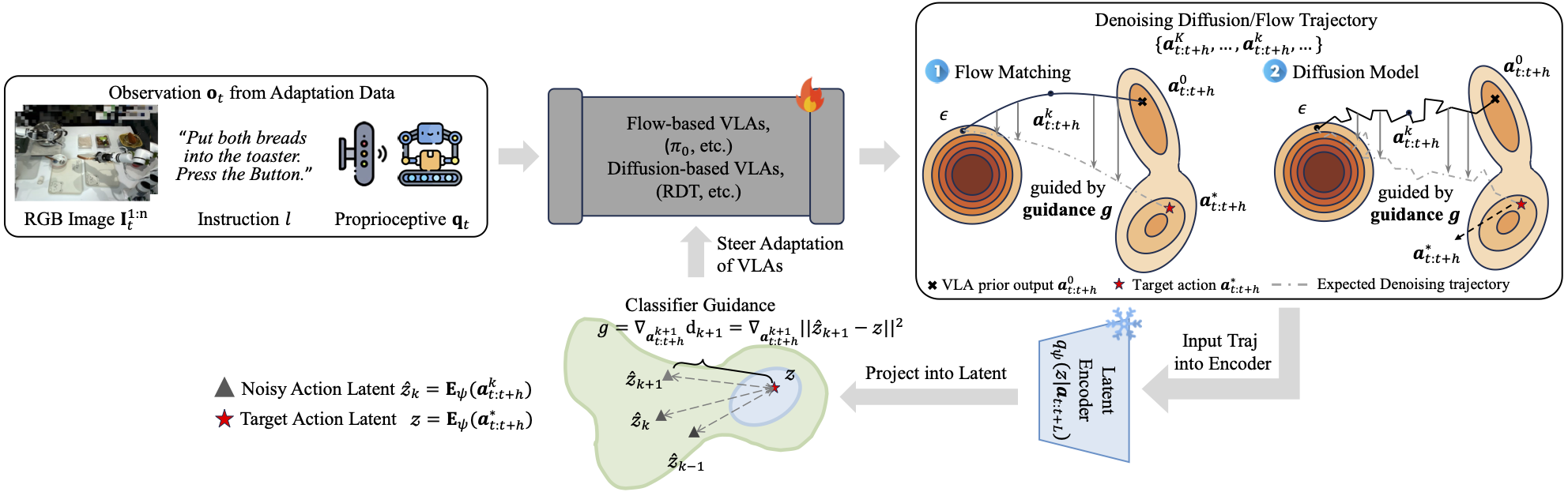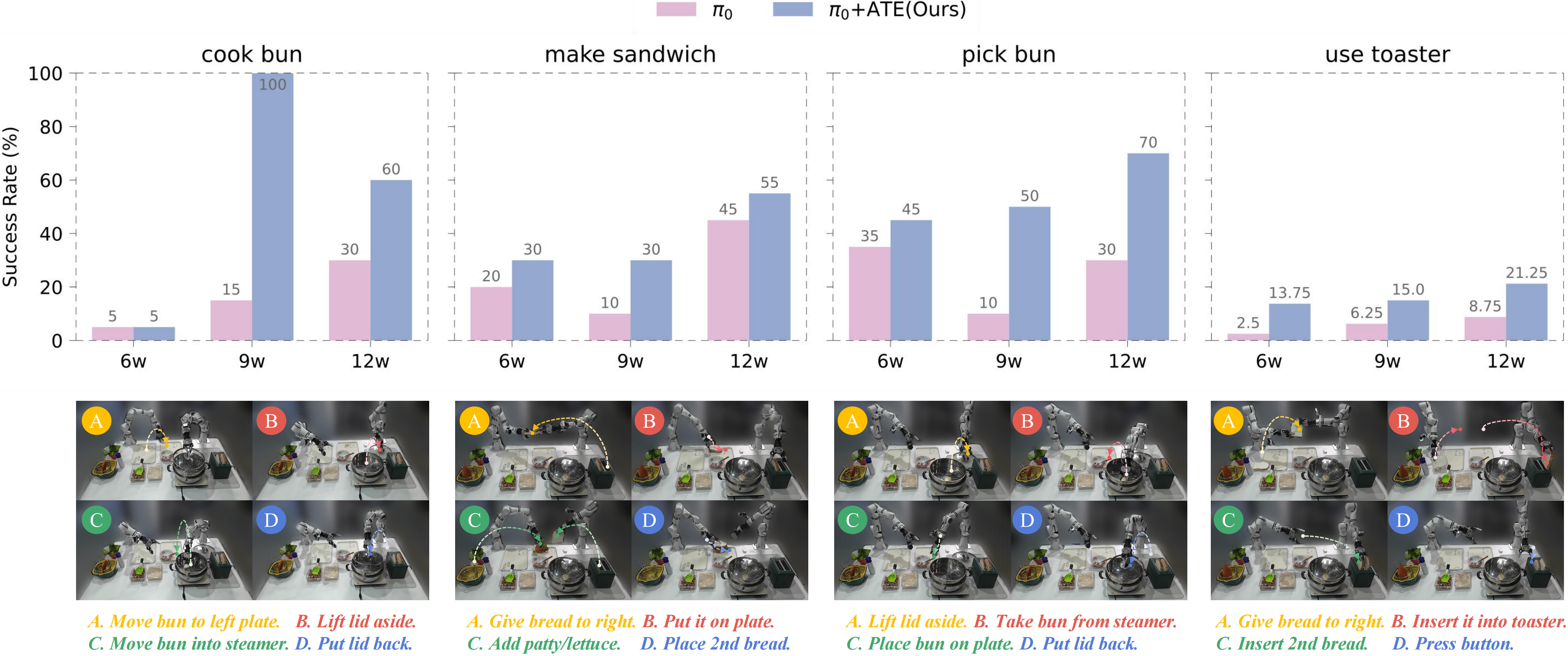
We present Align-Then-stEer (ATE), a plug-and-play adaptation framework for pre-trained Vision-Language-Action (VLA) models. Unlike prior methods that directly fine-tune VLAs, ATE aligns disparate action spaces into a unified latent representation and steers the diffusion- or flow-based VLA' s generation via guidance, enabling data-efficient cross-task and cross-embodiment adaptation. This framework is evaluated in simulation on RoboTwin and ManiSkill benchmarks, as well as on a real-world dual-arm RealMan 7-DoF robot, demonstrating strong generalization, bimanual dexterous coordination, and minute-level long-horizon manipulation, achieving substantial gains in multi-task success rates.